| Journal of Clinical Medicine Research, ISSN 1918-3003 print, 1918-3011 online, Open Access |
| Article copyright, the authors; Journal compilation copyright, J Clin Med Res and Elmer Press Inc |
| Journal website https://jocmr.elmerjournals.com |
Original Article
Volume 17, Number 11, November 2025, pages 653-662

Comparison of the SeizCT Primer and Optimized Models for Predicting Positive Computed Tomography Findings in Patients With Non-Traumatic Seizures
Natthaphon Pruksathorna ![]() , Thanin Lokeskraweea, g
, Thanin Lokeskraweea, g ![]() , Jarupa Yaowalaornga
, Jarupa Yaowalaornga ![]() , Suppachai Lawanaskolb
, Suppachai Lawanaskolb ![]() , Jayanton Patumanondc, Suwapim Chanlaord, Wanwisa Bumrungpagdeed, Chawalit Lakdeed, Kreshya Sudsanohe
, Jayanton Patumanondc, Suwapim Chanlaord, Wanwisa Bumrungpagdeed, Chawalit Lakdeed, Kreshya Sudsanohe ![]() , Pimploy Suriyanusornf
, Pimploy Suriyanusornf
aDepartment of Emergency Medicine, Lampang Hospital, Mueang District, Lampang 52000, Thailand
bChaiprakarn Hospital, Chiang Mai 50320, Thailand
cClinical Epidemiology and Clinical Statistics Unit, Faculty of Medicine, Naresuan University, Phitsanulok 65000, Thailand
dDepartment of Radiology, Buddhachinaraj Phitsanulok Hospital, Phitsanulok 65000, Thailand
eDepartment of Emergency Medicine, Phang Nga Hospital, Mueang District, Phang Nga 82000, Thailand
fDepartment of Emergency Medicine, Chomthong Hospital, Chomthong District, Chiangmai 50160, Thailand
gCorresponding Author: Thanin Lokeskrawee, Department of Emergency Medicine, Lampang Hospital, Mueang District, Lampang 52000, Thailand
Manuscript submitted August 31, 2025, accepted November 5, 2025, published online November 26, 2025
Short title: Comparison of SeizCT Models
doi: https://doi.org/10.14740/jocmr6375
| Abstract | ▴Top |
Background: Previous studies developed the SeizCT primer and optimized models, both demonstrating similar values for the area under the receiver operating characteristic curve (AuROC). The optimized model incorporates Glasgow Coma Scale (GCS) change from baseline instead of categorized GCS at emergency department (ED) presentation. This study aimed to validate these two models for predicting positive computed tomography (CT) findings in patients with non-traumatic seizures.
Methods: A retrospective cross-sectional study was conducted among adult patients (≥ 18 years) with non-traumatic seizures who underwent CT brain imaging in the ED at Lampang Hospital. Data were collected between December 2023 and July 2024 based on parameters from the SeizCT primer and optimized models. External validation compared model performance using AuROC, calibration, decision curve analysis (DCA), and confusion matrices.
Results: The validation cohort included 312 patients (210 (67.3%) male; mean age 53 years). Positive CT findings were found in 58 patients (18.6%). The SeizCT primer model had an AuROC of 0.7218 (95% confidence interval (CI): 0.6476, 0.7961), while the SeizCT optimized model achieved 0.7394 (95% CI: 0.6663, 0.8124). An equivalence test showed statistically equivalent discrimination between the two models (P < 0.015), with the optimized model demonstrating better calibration (slope: 0.582 vs. 0.701; P = 0.002; observed-to-expected ratio: 0.934 vs. 0.971; P = 0.030).
Conclusions: Both models demonstrated fair to acceptable discrimination after external validation. The SeizCT optimized model is recommended, as it showed superior calibration and its incorporation of GCS change from baseline offers greater clinical applicability.
Keywords: Seizures; Tomography; X-ray computed; Validation; Diagnosis; Mobile applications
| Introduction | ▴Top |
Seizures are a common neurological emergency and a frequent reason for visits to the emergency department (ED). In Turkey, 814 patients with seizures underwent computed tomography (CT) head scans. Positive findings were observed in 21.4% of cases, but management was altered in only 10.4% [1]. In Thailand, most EDs - and especially Lampang Hospital - perform CT head scans for nearly all patients presenting with a seizure, resulting in more than 90% coverage in practice. Although this has not yet been formally published, it persists despite ongoing concerns about low diagnostic yield, high cost, and radiation exposure. To address this issue, previous studies developed clinical prediction models (CPMs) - the SeizCT primer model [2], followed by the SeizCT optimized model [3] - to help identify patients more likely to have positive CT findings and reduce unnecessary imaging. The primary difference between the two lies in one key predictor: the SeizCT primer model uses categorized Glasgow Coma Scale (GCS) scores at ED presentation, whereas the SeizCT optimized model incorporates GCS change from baseline. Despite this distinction, both models demonstrated similar areas under the receiver operating characteristic curve (AuROC) values in their original studies.
More broadly, CPMs across various domains often remain unvalidated beyond their original settings. Approximately 76% of all CPMs lack external validation [4], representing a critical gap. External validation, recognized as phase 2 in the model development hierarchy, is essential for assessing generalizability.
Therefore, this study aims to externally validate and compare the performance of the SeizCT primer and SeizCT optimized models using a new dataset.
| Materials and Methods | ▴Top |
Study design
This diagnostic prediction research employed a retrospective, observational, cross-sectional design for temporal external validation. The study was conducted in the ED of Lampang Hospital, a tertiary regional center in Northern Thailand with approximately 75,000 annual ED visits. Data collection took place between December 2023 and July 2024. Baseline characteristics and model-specific parameters were collected in accordance with the SeizCT primer and SeizCT optimized models.
Participant and data collection
Participants
Adults aged 18 years or older who presented with non-traumatic seizures and underwent non-contrast CT head scans were eligible for inclusion. Exclusion criteria included: 1) documented or suspected traumatic brain injury (TBI) within the prior 30 days [5]; 2) inconclusive expert consensus on CT findings as the cause of seizure; 3) absence of a recorded baseline GCS or a reliable caregiver/family member to assess the patient’s usual level of consciousness; and 4) pregnancy. The CT head scan was performed after completion of the primary and secondary assessments, accompanied by capillary blood glucose (CBG) measurement and blood collection for laboratory tests.
Definition
A non-traumatic seizure was defined as a seizure not related to TBI within 30 days after the injury, consistent with the timeframe used in prior literature distinguishing post-traumatic from unprovoked seizures [3, 5].
Endpoints [3]
The primary endpoint was a positive CT head scan, defined as the detection of one or more lesions on imaging, such as intracerebral hemorrhage, subarachnoid hemorrhage, acute infarction, arachnoid or subarachnoid cysts, neurocysticercosis, tuberculoma, granulomatous lesions, calcifications, tumors, malignancies, brain metastases, cerebral edema, arteriovenous malformation (AVM), cerebral venous sinus thrombosis, or hydrocephalus [6-8]. Whether a detected lesion was likely to have precipitated the seizure was determined through majority agreement among three qualified specialists - a neurologist, a neurosurgeon, and a radiologist - each with more than 10 years of clinical experience and not listed as co-authors. All reviewers were blinded to each other’s interpretations and to the patients’ clinical predictor data. Inter-rater agreement was high, with a kappa statistic of 0.8517. Cases in which the panel’s assessment was inconclusive, with no definitive link established between the lesion and the seizure, were excluded from the analysis.
Old structural or non-progressive brain lesions were interpreted as negative CT brain findings. Old infarctions incidentally detected without corresponding clinical stroke symptoms were also classified as negative.
Predictors [3]
The predictors used in this external validation were the same as those in the development studies of the SeizCT primer and SeizCT optimized models. Both models included six predictors: focal neurological deficit, current cancer, alcohol withdrawal symptoms (AWS), epilepsy, prior stroke more than 3 months earlier, and a GCS-related measure. The difference between the two models lies in the GCS variable: the SeizCT primer model used GCS at presentation categorized into three groups (≤ 8, 9 - 13, and > 13) [2], whereas the SeizCT optimized model used GCS change from baseline, calculated as the GCS score at presentation minus the documented baseline GCS from the medical record or a reliable caregiver’s report. All predictor definitions and coding followed the criteria specified in the original development studies.
These predictors were obtained following the completion of primary and secondary assessments by physicians.
The GCS was initially assessed by a trained and experienced triage nurse and subsequently re-evaluated by a physician upon patient assessment. Both scores were recorded at different times in the electronic medical record (EMR) according to international standards and educational practice [9]; if a discrepancy occurred, the physician’s GCS was used, as the score may change over time.
To mitigate information bias, the collection of predictors and endpoints was performed by separate team members.
Specific time point of prediction
The prediction step was performed after the initial clinical evaluation, subsequent to CBG testing and blood sampling for laboratory analysis, and just before the decision to proceed with a CT head scan.
Study size estimation
The sample size was calculated using the mean AuROC from the SeizCT primer model (0.8156) [2] and the SeizCT optimized model (0.8221) [3], yielding an average AuROC of 0.8189. An equivalence test with a two-sided significance level (α) of < 0.05, 80% power, incorporating an acceptable equivalence margin of ±10% [10] was applied. Taking into account the distribution of positive CT findings (n = 59) and negative findings (n = 253), the total sample size was 312 patients.
Missing data
The main missing data involved the verbal component of the GCS, most often recorded as “T,” indicating patients with either a tracheostomy or endotracheal intubation (ETI). In the retrospective review, it was not documented whether these patients could communicate effectively. To address this, we applied data imputation [11]. Ordinal logistic regression was performed separately for the tracheostomy and ETI groups, using the eye and motor components of the GCS as predictors to estimate the verbal score. For each case, the model generated five probability values, and the imputed verbal score was assigned based on the highest predicted probability. Pupil size data were also missing in some cases; however, this variable was not imputed because it was not among the candidate predictors.
Statistical analysis
Differences between datasets
Baseline characteristics were compared across the three cohorts using the exact probability test for categorical variables, and one-way analysis of variance (ANOVA) or the Kruskal-Wallis test for continuous variables, depending on data distribution.
Prediction calculation for model validation
Predicted probabilities for positive CT findings were calculated for each patient in the validation dataset using the original logistic regression formulas derived from the SeizCT primer and SeizCT optimized models. Each model’s intercept and beta coefficients were applied directly without recalibration. The predictor variables in the validation cohort were coded identically to the derivation study to ensure consistency.
In the previous study [3], the term “history of malignancy” was revised to “current cancer” to more accurately reflect active or ongoing disease. Similarly, “history of cerebrovascular accident (CVA)” was replaced with “prior stroke more than 3 months.” We adopt the same terminology in this study.
For the SeizCT primer model, the formula included categorized GCS in three groups at presentation, focal neurological deficit, current cancer, AWS, epilepsy, and prior stroke more than 3 months. Logit-based predicted probabilities were then computed using the following formula [2]:
For the SeizCT optimized model, the same predictors were used, except that the predictor “categorized GCS” was replaced by “GCS change from baseline”. A separate logistic regression formula, reflecting this revised predictor set, was used to calculate predicted probabilities and is presented below [3].
Model performance
Model performance was compared between the SeizCT primer and SeizCT optimized models across four domains: discrimination, calibration, clinical utility, and classification performance.
Discrimination was quantified by the AuROC with 95% confidence intervals (CIs). Because the original models demonstrated similar AuROC values, an equivalence P value was calculated to formally test whether their discriminative performance was statistically equivalent.
Calibration was assessed using calibration plots, the observed-to-expected (O:E) ratio, the calibration slope, and the calibration-in-the-large (CITL), with conventional P values applied to compare agreement between predicted and observed risks.
Clinical utility was evaluated using decision curve analysis (DCA), comparing net benefit across clinically relevant threshold probabilities. Classification performance was summarized with confusion matrix metrics at a prespecified probability cutoff, targeting a false negative (FN) proportion < 5% and a false positive (FP) proportion < 15% as clinically acceptable.
The study protocol was registered with the Thai Clinical Trials Registry (TCTR; TCTR20250829002). The Institutional Review Board of Lampang Hospital approved the study protocol (CERT No. 121/67). The study was conducted in accordance with the principles of the Declaration of Helsinki. Informed consent was waived due to the observational nature of the study.
This study was conducted and reported in accordance with the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD) guideline [12].
| Results | ▴Top |
Adult patients with non-traumatic seizures presenting between December 2023 and July 2024 were included. After exclusions, 312 patients remained eligible, from whom predictors for both models were collected. Positive CT findings were observed in 58 cases, while the remaining 254 were negative, yielding a prevalence of 18.6% (Fig. 1).
 Click for large image | Figure 1. Study flow diagram. GCS: Glasgow Coma Scale; AuROC: area under the receiver operating characteristic curve; O:E ratio: observed-to-expected ratio; CITL: calibration-in-the-large. |
Of the 312 patients, 210 (67.3%) were male, with a mean age of 53.4 ± 17.5 years. Verbal scores were imputed for 17 patients (5.4%), including six with tracheostomy and 11 with ETI. Pupil size data were missing in 40 patients (12.8%), while anisocoria was rare.
Prior stroke and abnormal findings on previous CT brain were more common in the validation cohort; importantly, these previous CT findings were not related to the study endpoint of positive CT brain results. Hypertension and chronic liver disease were also more frequent in this cohort, whereas male sex, alcohol consumption and AWS were less common. In contrast, the verbal component of the GCS and focal neurological deficits were least frequent in the SeizCT primer model (Table 1).
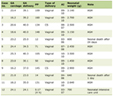 Click to view | Table 1. Baseline Characteristics of Patients in the SeizCT Primer, SeizCT Optimized, and External Validation Cohorts |
Model performance
In the development studies, the original AuROC was 0.8156 (95% CI: 0.7586, 0.8727) for the SeizCT primer model and 0.8221 (95% CI: 0.7813, 0.8629) for the SeizCT optimized model. After external validation, the AuROC decreased to 0.7218 (95% CI: 0.6476, 0.7961) for the primer model and 0.7394 (95% CI: 0.6663, 0.8124) for the optimized model, indicating a decline of approximately 10% in discriminative ability for both models. The equivalence test confirmed that the two models had statistically equivalent discriminative performance (P < 0.015) (Fig. 2).
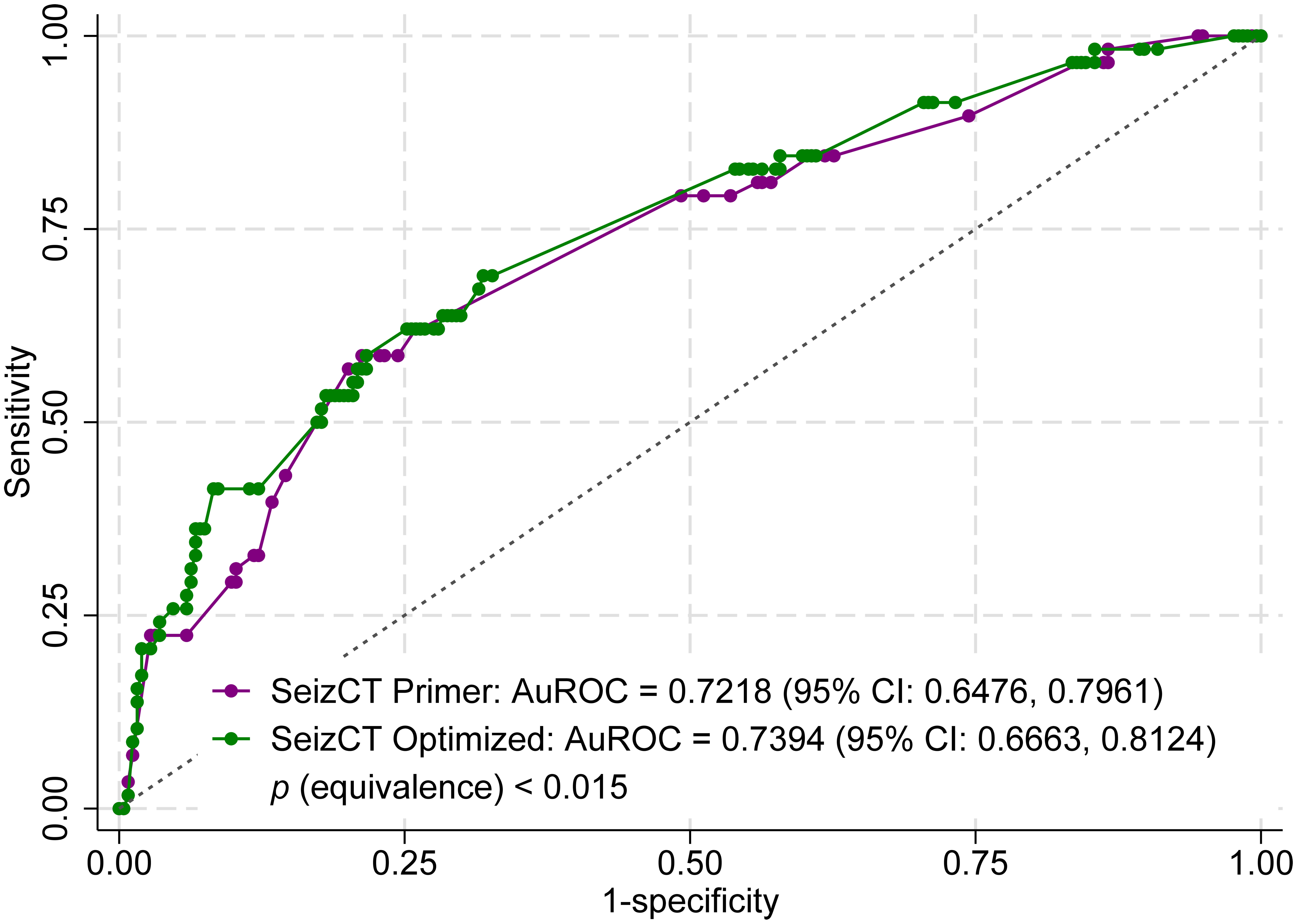 Click for large image | Figure 2. Receiver operating characteristic (ROC) curves comparing the SeizCT primer and optimized models using equivalence testing. CI: confidence interval. |
Other performance metrics also showed moderate calibration. The calibration slope was 0.582 (95% CI: 0.358, 0.805) in the primer model vs. 0.701 (95% CI: 0.454, 0.948) in the optimized model (P = 0.002), indicating improved calibration and reduced overfitting in the latter. The O:E ratios were also significantly closer to unity in the optimized model (0.934 vs. 0.971; P = 0.030), reflecting better agreement between predicted and observed outcomes. In contrast, CITL did not differ significantly between models (-0.112 vs. -0.048; P = 0.783), with both values close to zero, suggesting minimal systematic underprediction or overprediction. Overall, these findings demonstrate that the optimized model provided significantly better calibration on slope and O:E ratio, while maintaining comparable CITL performance (Table 2, Fig. 3).
Click to view | Table 2. Predictive Performance of the SeizCT Primer and SeizCT Optimized Models in the External Validation Cohort |
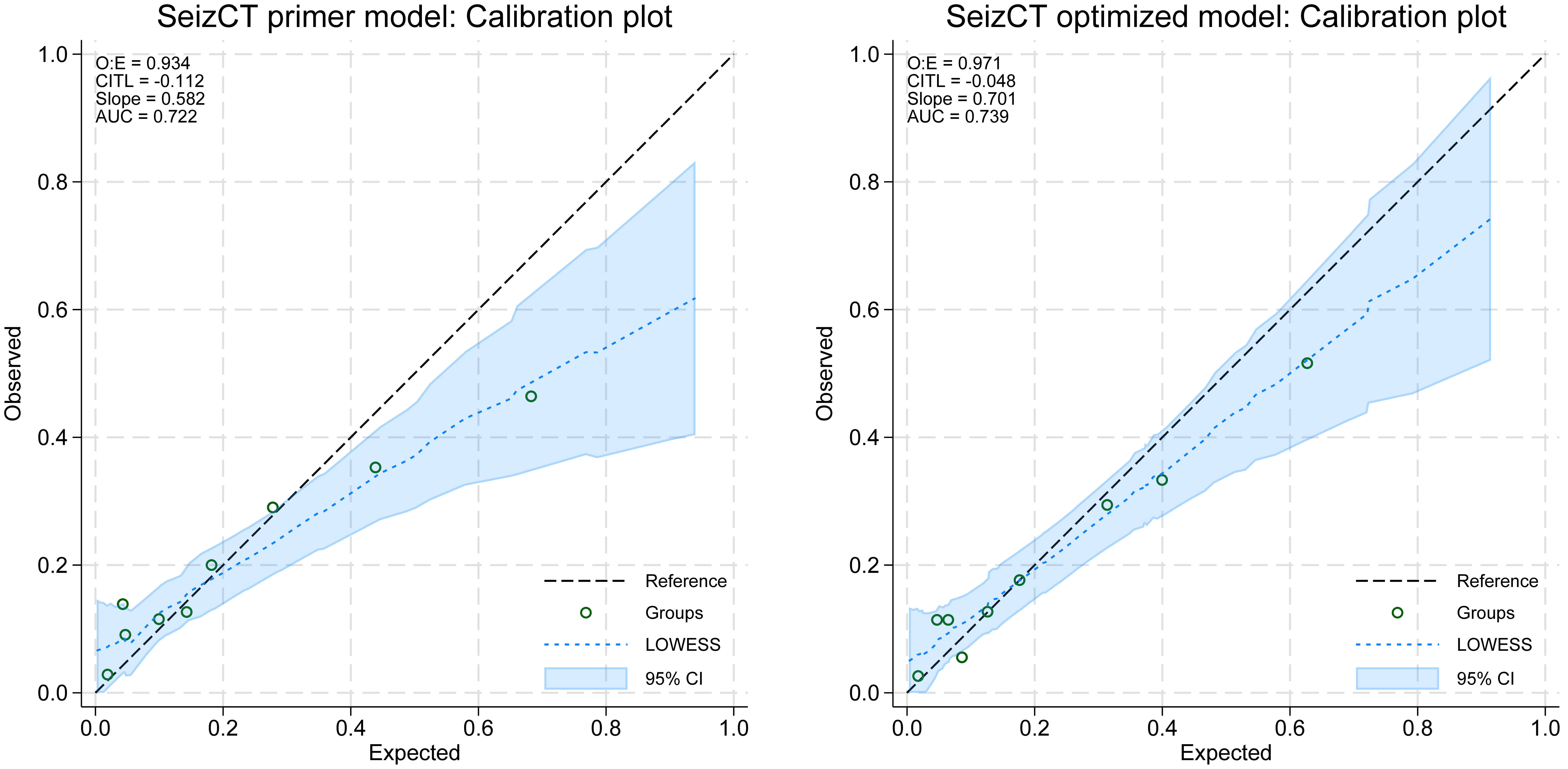 Click for large image | Figure 3. Calibration plots of the SeizCT primer and optimized models. AUC: area under the curve; O:E ratio: observed-to-expected ratio; CITL: calibration-in-the-large; CI: confidence interval. |
In this validation cohort, DCA demonstrated less favorable performance compared with the original derivation studies. The net benefit of model use became apparent only at a prevalence of 19% or higher (Fig. 4), whereas in the original models, clinical benefit was observed beginning at a prevalence threshold of 10% [2, 3].
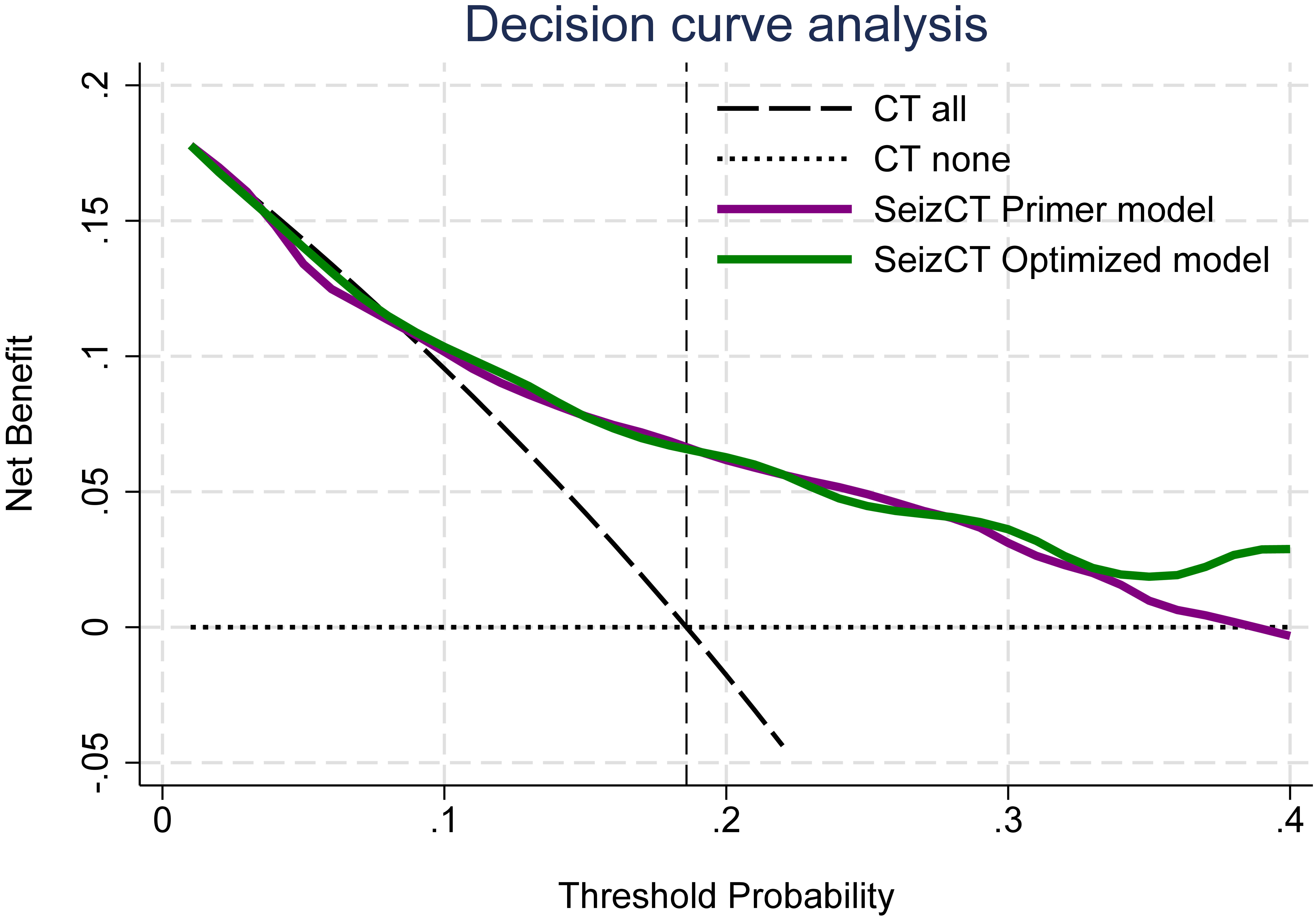 Click for large image | Figure 4. Decision curve analysis of the SeizCT primer and optimized models. CT: computed tomography. |
Both models were designed with predefined acceptable thresholds of an FN proportion not exceeding 5% and an FP proportion not exceeding 15%. After external validation, however, both models yielded FN and FP proportions beyond these limits. The SeizCT primer model showed a higher FP proportion (18.9% vs. 17.0%), whereas the SeizCT optimized model exhibited a slightly higher FN proportion (7.7% vs. 8.0%) (Table 3).
Click to view | Table 3. Confusion Matrix of the SeizCT Primer and SeizCT Optimized Models in the External Validation Cohort |
| Discussion | ▴Top |
In the United States, patients with established epilepsy have typically undergone prior neuroimaging, and the underlying cause of their condition is already known; therefore, brain imaging is generally not performed when such patients present to the ED with a seizure [13]. In contrast, the situation in Thailand differs. Physicians are often concerned about potential misdiagnosis, as there have been instances in which patients with known epilepsy were later found to have positive CT brain findings after discharge or admission, which could reflect negatively on the emergency physician. Consequently, most EDs in Thailand perform CT head scans for nearly all patients presenting with seizures - both first episode and recurrent - resulting in more than 90% imaging coverage. This practice contributes to over-investigation, increased radiation exposure, and higher healthcare costs. These challenges prompted the development of the SeizCT primer model [2], followed by the SeizCT optimized model [3], which aim to identify patients at higher risk who truly warrant CT brain imaging.
In this external validation study, the SeizCT primer and optimized models demonstrated comparable discriminative performance. Both models achieved similar AuROC values, indicating that their ability to distinguish patients with positive CT findings remained close after validation. This finding is consistent with their original development, where the discriminative performances were already closely aligned.
However, compared with their development datasets, the AuROC decreased by approximately 10% for both models - a reduction commonly observed when CPMs are applied to new populations. Several factors may explain this decline. First, the original models may have been overfitted, while differences in baseline characteristics between cohorts likely influenced performance, including smaller GCS changes from baseline, a lower prevalence of AWS, and a higher prevalence of prior stroke in the validation cohort. Second, while GCS change from baseline is a clinically intuitive predictor, its accuracy depends on reliable documentation in the medical record. Although we pre-specified in the Methods that only cases with trustworthy informants were enrolled, the exclusion of patients without EMR documentation of baseline GCS inevitably limits generalizability of the findings to routine practice. Moreover, GCS assessment - particularly the verbal component - was not imputed in either of the previous models, creating inconsistencies between datasets. Future studies should incorporate appropriate imputation strategies to mitigate this limitation. Finally, the low proportion of bedridden patients or those with low baseline GCS in this cohort limited the ability to highlight differences between the two models, suggesting that further validation in populations enriched with such patients would be informative.
Beyond discrimination, calibration analyses highlighted meaningful differences between the two models. The optimized model demonstrated a steeper calibration slope and an O:E ratio closer to unity, indicating better agreement between predicted and observed outcomes as well as reduced overfitting. By contrast, CITL was similarly close to zero in both models, suggesting little systematic bias. Taken together, these findings show that although discrimination declined modestly on external validation, the optimized model retained a clear advantage in calibration compared with the primer model.
The study size was calculated using an equivalence test rather than a conventional test of differences in AuROC. A superiority approach aimed at detecting very small differences between the two models would have required an unfeasibly large sample size, potentially exceeding 50,000 patients. Given that the original AuROC values of the primer and optimized models were already very similar, our objective was not to demonstrate superiority but to confirm equivalence in discriminative performance. Therefore, an equivalent framework was chosen for sample size estimation.
Based on the predefined calculation, 59 patients with positive CT findings and 253 with negative CT findings were required. In practice, the validation cohort included 58 positive and 254 negative cases. These numbers arose from consecutive data collection, without selective inclusion or exclusion, resulting in the positive CT group having only one patient fewer than the prespecified target. Such a minimal shortfall is unlikely to affect the validity of the study.
Evaluation of confusion matrices showed that both models exceeded their predefined error thresholds (< 5% for FN and < 15% for FP). The primer model had a greater tendency toward FP, whereas the optimized model showed a slightly higher FN proportion. In multidisciplinary discussions with emergency physicians, neurologists, and neurosurgeons, consensus was reached to prioritize patient safety by maintaining FN below 5%. However, for future research, we propose relaxing the FP threshold to < 20%. This adjustment, although allowing slightly more FP, would remain safer and more efficient than performing CT scans in all seizure patients. Moreover, such a threshold modification is essential to advance toward phase II or III validation of the clinical prediction rule [14]; without it, research efforts would remain confined to repetitive re-derivation and external validation cycles, as declining performance often prevents models from meeting overly stringent thresholds.
In Western studies, prior stroke has generally not been analyzed as a factor of interest associated with positive neuroimaging findings - either CT or magnetic resonance imaging (MRI) - in patients presenting with seizures, likely because it represents chronic rather than acute pathology and therefore contributes little to detecting new structural lesions [15, 16]. Only one study from Saudi Arabia reported an inverse association, showing that a history of stroke decreased the odds of abnormal CT brain findings [17]. This result aligns closely with the Thai studies by Suriyanusorn et al [2] and Sudsanoh et al [3], in which old infarct lesions on CT brain were interpreted as negative findings. In that study, three predictors - prior stroke more than 3 months, AWS, and epilepsy - acted as protective factors against positive CT findings. The negative association with prior stroke can be explained by old infarct scars that may initiate seizures through neuronal hyperexcitability rather than indicating new pathology [18].
Although this study did not directly collect data on “first-episode seizure,” an indirect estimation was performed using two criteria: 1) absence of prior epilepsy history; and 2) first seizure presentation within this cohort. Based on these criteria, positive CT brain findings occurred in 23.0% of patients with first-episode seizures and 7.0% with recurrent seizures (P = 0.001), consistent with findings from Iran [8]. The differing proportions of positive CT findings between these groups suggest a potential effect modifier. Incorporating the “first-episode seizure” variable in subsequent model refinements may further enhance diagnostic performance, while collecting final clinical diagnoses in future research would help clarify the clinical domain and better characterize the study population.
Conclusions
Both SeizCT models showed similar discriminative ability after external validation, with an approximate 10% decline in AuROC compared with their derivation phases, indicating fair to acceptable discrimination. The SeizCT optimized model is recommended, as it demonstrated superior calibration, and its use of GCS change from baseline enhances clinical practicality.
Acknowledgments
This study was supported by the Lampang Medical Education Center. The authors would like to thank the emergency medicine residents, staff, and registered nurses at the Department of Emergency Medicine, Lampang Hospital.
Financial Disclosure
This study was supported by the Lampang Medical Education Center.
Conflict of Interest
The authors reported no conflict of interest related to the contents of the article.
Informed Consent
Informed consent was waived due to the observational nature of the study.
Author Contributions
Conceptualization: Natthaphon Pruksathorn, Thanin Lokeskrawee, Suppachai Lawanaskol, Jayanton Patumanond. Data curation: Natthaphon Pruksathorn. Formal analysis: Natthaphon Pruksathorn, Jarupa Yaowalaorng, Suwapim Chanlaor, Wanwisa Bumrungpagdee, Chawalit Lakdee, Thanin Lokeskrawee, Suppachai Lawanaskol, Jayanton Patumanond. Methodology: Natthaphon Pruksathorn, Thanin Lokeskrawee, Suppachai Lawanaskol, Jayanton Patumanond. Supervision: Thanin Lokeskrawee, Pimploy Suriyanusorn, Kreshya Sudsanoh, Suppachai Lawanaskol, Jayanton Patumanond. Writing - original draft: Natthaphon Pruksathorn, Thanin Lokeskrawee, Suppachai Lawanaskol, Jayanton Patumanond.
Data Availability
Any inquiries regarding supporting data availability of this study should be directed to the corresponding author. The SeizCT models are available as web-based calculators at the following links: 1) SeizCT primer model: https://tharathipdevelop.com/pos-ct/form; 2) SeizCT optimized model: https://tharathipdevelop.com/pos-ct2/form.
| References | ▴Top |
- Sever M, Cicek G, Ocak NY, Eyler Y, Toktas R, Toker I, et al. Non-contrast cranial computed tomography can change the emergency management of nontraumatic seizure patients. Signa Vitae. 2020;16(1):105-114.
- Suriyanusorn P, Lokeskrawee T, Patumanond J, Lawanaskol S, Wongyikul P. Development of clinical prediction model to guide the use of CT head scans for non-traumatic Thai patient with seizure: A cross-sectional study. PLoS One. 2024;19(7):e0305484.
doi pubmed - Sudsanoh K, Lokeskrawee T, Pruksathorn N, Lawanaskol S, Patumanond J, Bumrungpagdee W, Chanlaor S, et al. Improving a clinical prediction model for computed tomography head scan use in non-traumatic seizures: the SeizCT optimized model. J Clin Med Res. 2025;17(7):398-407.
doi pubmed - Hueting TA, van Maaren MC, Hendriks MP, Koffijberg H, Siesling S. External validation of 87 clinical prediction models supporting clinical decisions for breast cancer patients. Breast. 2023;69:382-391.
doi pubmed - Garga N, Lowenstein DH. Posttraumatic epilepsy: a major problem in desperate need of major advances. Epilepsy Curr. 2006;6(1):1-5.
doi pubmed - Acharya S, Tiwari A, Shrestha A, Sharma R, Shakya R. Computed tomography findings in patients with seizure disorder. J Lumbini Med Coll. 2016;4(1):7-10.
- Patil NBS, Wadhwani ND. Analysis of CT scans findings in seizures patients: an observational study. Asian J Med Radio Res;7(2):4-6.
- Zarmehri B, Teimouri A, Ebrahimipour N, Foroughian M, Talebzadeh V, Saeidi M, Alirezaei M. Brain CT findings in patients with first-onset seizure visiting the emergency department in Mashhad, Iran. Open Access Emerg Med. 2020;12:159-162.
doi pubmed - Cook N, Trout R, Waterhouse C, Braine M, Barrett C, Brennan P, et al. The Glasgow Coma Scale: An international standard for education and practice with adults. British J Neurosci Nurs. 2025;21(Sup1c):S1-S36.
- Liu JP, Ma MC, Wu CY, Tai JY. Tests of equivalence and non-inferiority for diagnostic accuracy based on the paired areas under ROC curves. Stat Med. 2006;25(7):1219-1238.
doi pubmed - Sisk R, Sperrin M, Peek N, van Smeden M, Martin GP. Imputation and missing indicators for handling missing data in the development and deployment of clinical prediction models: A simulation study. Stat Methods Med Res. 2023;32(8):1461-1477.
doi pubmed - Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. BMJ. 2015;350:g7594.
doi pubmed - Kvam KA, Douglas VC, Whetstone WD, Josephson SA, Betjemann JP. Yield of emergent CT in patients with epilepsy presenting with a seizure. Neurohospitalist. 2019;9(2):71-78.
doi pubmed - Binuya MAE, Engelhardt EG, Schats W, Schmidt MK, Steyerberg EW. Methodological guidance for the evaluation and updating of clinical prediction models: a systematic review. BMC Med Res Methodol. 2022;22(1):316.
doi pubmed - Tranvinh E, Lanzman B, Provenzale J, Wintermark M. Imaging evaluation of the adult presenting with new-onset seizure. AJR Am J Roentgenol. 2019;212(1):15-25.
doi pubmed - Camilo O, Goldstein LB. Seizures and epilepsy after ischemic stroke. Stroke. 2004;35(7):1769-1775.
doi pubmed - Alhusain F, Nasradeen M, Althunayan M, Alomar R, Alqahtani N, Amer R, et al. Neuroimaging patterns in adult patients with new-onset seizures: A five-year emergency department study in Riyadh. Saudi J Emerg Med. 2025;6(3):195-200.
- Galovic M, Dohler N, Erdelyi-Canavese B, Felbecker A, Siebel P, Conrad J, Evers S, et al. Prediction of late seizures after ischaemic stroke with a novel prognostic model (the SeLECT score): a multivariable prediction model development and validation study. Lancet Neurol. 2018;17(2):143-152.
doi pubmed
This article is distributed under the terms of the Creative Commons Attribution Non-Commercial 4.0 International License, which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
Journal of Clinical Medicine Research is published by Elmer Press Inc.